Memory safety
The Chromium project finds that around 70% of our serious security bugs are memory safety problems. Our next major project is to prevent such bugs at source.
The problem
Around 70% of our high severity security bugs are memory unsafety problems (that is, mistakes with C/C++ pointers). Half of those are use-after-free bugs.
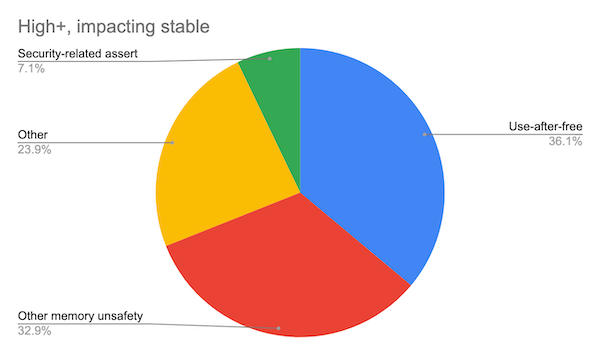
(Analysis based on 912 high or critical severity security bugs since 2015, affecting the Stable channel.)
These bugs are spread evenly across our codebase, and a high proportion of our non-security stability bugs share the same types of root cause. As well as risking our users’ security, these bugs have real costs in how we fix and ship Chrome.
The limits of sandboxing
Chromium’s security architecture has always been designed to assume that these bugs exist, and code is sandboxed to stop them taking over the host machine. Over the past years that architecture has been enhanced to ensure that websites are isolated from one another. That huge effort has allowed us — just — to stay ahead of the attackers. But we are reaching the limits of sandboxing and site isolation.
A key limitation is that the process is the smallest unit of isolation, but processes are not cheap. Especially on Android, using more processes impacts device health overall: background activities (other applications and browser tabs) get killed with far greater frequency.
We still have processes sharing information about multiple sites. For example, the network service is a large component written in C++ whose job is parsing very complex inputs from any maniac on the network. This is what we call “the doom zone” in our Rule Of 2 policy: the network service is a large, soft target and vulnerabilities there are of Critical severity.
Just as Site Isolation improved safety by tying renderers to specific sites, we can imagine doing the same with the network service: we could have many network service processes, each tied to a site or (preferably) an origin. That would be beautiful, and would hugely reduce the severity of network service compromise. However, it would also explode the number of processes Chromium needs, with all the efficiency concerns that raises.
Meanwhile, our insistence on the Rule Of 2 is preventing Chrome developers from shipping features, as it’s already sometimes just too expensive to start a new process to handle untrustworthy data.
Staying still is not an option
We believe that:
Attackers innovate, so defenders need to innovate just to keep pace.
We can no longer derive sufficient innovation from more processes or
stronger sandboxes (though such things continue to be necessary).
Therefore the cheapest way to maintain the advantage is to squash bugs at
source instead of trying to contain them later.
What we’re trying
We’re tackling the memory unsafety problem — fixing classes of bugs at scale, rather than merely containing them — by any and all means necessary, including:
- Custom C++ libraries
- //base is already getting into shape for spatial memory safety.
- std and Abseil assume correct callers ‘for speed’, but can be modified to do basic checking with implementation changes (Abseil) and compile-time flags (LLVM libcxx).
- Generalizing Blink’s C++ garbage collector, and using it more widely (starting with PDFium).
- Hardware mitigations, e.g.
MTE.
- Custom C++ dialect(s)
- Defined and enforced by LLVM plugins and presubmit checks. In particular, we feel it may be necessary to ban raw pointers from C++.
- Using safer languages anywhere applicable
- Java and Kotlin
- JavaScript
- Rust (see our notes on C++ interoperability here)
- Swift
- Others…?
These options lie on a spectrum:

We expect this strategy will boil down to two major strands:
Significant changes to the C++ developer experience, with some performance
impact. (For instance, no raw pointers, bounds checks, and garbage
collection.)
An option of a programming language designed for compile-time safety checks
with less runtime performance impact — but obviously there is a cost to
bridge between C++ and that new language.